How to Fix ChatGPT You are being Rate Limited?

ChatGPT is a chatbot with cutting-edge AI technology to generate lifelike and engaging conversations. However, you may encounter an error message stating “you are being rate limited” or “Error code: 429”. This indicates that you have exceeded the maximum number of requests allowed by the ChatGPT server and must wait before using it again.
Many people encounter this ChatGPT You Are Being Rate Limited error on a daily basis. However, if you’re unaware of how to fix the “you are being rate limited” issue on ChatGPT, we’ve got you covered. To fix the error, the article will also cover ways to get back to using ChatGPT normally. Without further ado, let’s dive right into it!

Fix ChatGPT You are being Rate Limited
What is Rate Limit?
Rate limits serve as a mechanism for regulating and managing application or service usage. Typically, they are implemented at two levels: IP-based and API-based.
IP-based rate limits restrict the number of queries or actions executed from a specific IP address within a given time frame. This method ensures equitable utilization and prevents abusive or excessive traffic from a single source.
API-based rate limits, on the other hand, restrict the number of API requests that can be performed within a given time. This form of rate limiting is frequently used to regulate web services and APIs.
What Does ChatGPT Global Rate Limit/API Rate Limit Exceeded Error Mean?
The “ChatGPT Global Rate Limit/API Rate Limit Exceeded” error indicates that the rate at which requests to the ChatGPT service are made has exceeded the specified limit. The HTTP status code 429 is widely used to signify this problem.
ChatGPT’s rate restriction is intended to provide optimum performance, minimize misuse, and preserve system stability. The error message tells users that they have made too many requests in a short period. It protects against excessive use, which might negatively affect the overall operation of the ChatGPT service.
Why is Your ChatGPT Being Rate Limited?
Your ChatGPT can rate limited because of many reasons. Here’s a list of some of the common ones:
- Generating too many requests/protections against misuse–ChatGPT has a rate restriction in place to avoid abusive usage if too many requests are made to the API quickly. The rate restriction prevents service abuse and keeps the API accessible to legitimate users.
- Server overload– Overloading the ChatGPT server might cause it to become unresponsive or completely stop working. This can degrade the service’s overall quality and make it unavailable to certain users.
- Network issues– ChatGPT API access may fail if your internet connection is sluggish, unreliable, or often interrupted. Your queries may experience delays, problems, or timeouts as a result.
- Browser issues– You may have trouble utilizing the ChatGPT service if your browser is old, unsupported, or corrupted. This may alter the service’s behavior and how it appears on your gadget.
What will happen if I hit the rate limit on ChatGPT?
You will receive an error message stating “you are being rate limited” or “Error code: 429” if you exceed the rate limit on ChatGPT.
This indicates that you have reached your limit and must wait a period before you can use the service again. Alternatively, you may request an increase in your rate limit or upgrade your plan.
Difference between rate limit and Max_tokens?
RPM (requests per minute) and TPM (tokens per minute) measure the rate limit. RPM is the number of API requests per minute that can be made to the ChatGPT API. TPM is the maximum number of tokens that can be used in one minute.
A token is a word fragment utilized for natural language processing. Max_tokens specify the maximum number of tokens permitted in a single request.
Does OpenAI free trial has limits?
Yes, the OpenAI trial has limitations. During your first three months, you can access $5 in complimentary credit.
Additionally, you can utilize models with varying capabilities and prices. ChatGPT models have a rate limit of 3 RPM and 150,000 TPM for free trial users.
How to Fix Your ChatGPT Global Rate Limit Exceeded
Now that you understand what the error is about and its reasons, it’s time you learn all solutions to fix it or avoid it. Here’s a list of the solutions to implement:
Reduce the frequency and complexity of your queries
Reduce the requests you make to the ChatGPT API in a particular period to avoid reaching the rate restriction. You may also minimize query complexity by using fewer tokens or clearer instructions. This will allow you to utilize fewer resources while staying within your limit.
Monitor API usage
Another technique to prevent exceeding the rate limit is to watch your API use and how many requests and tokens you use. The dashboard displays your current and past consumption and the status of your rate limit.
Set usage limit
Setting a use restriction for your company or application is a third option to prevent exceeding the rate limit. Through the account administration page, you may establish a maximum monthly cost or a hard limit for the API. This will assist you in maintaining financial management and avoiding unexpected expenditures.
Exponential backoff
When you encounter an error, you may utilize exponential backoff to prevent reaching the rate limit. The approach of exponential backoff entails waiting for a longer amount of time before retrying a failed request. With each successive failure, the waiting time climbs exponentially until a maximum value is attained.
Use caching
A fifth technique to avoid exceeding the rate restriction is to cache your queries. Caching is a strategy that saves prior request results and reuses them wherever feasible rather than generating new ones. This will allow you to save money and increase performance.
Apply rate limiting at the client side
The client side may implement rate restriction by restricting the number of requests a user can make in a certain time window. This strategy may assist in minimizing the number of queries made to the server while preventing rate-limit issues.
Check the status of OpenAI
If ChatGPT is unavailable or undergoing maintenance, multiple errors, malfunctions, or defects may manifest, including excessive requests. So, proceed to verify the server’s health.
Step 1. Visit the OpenAI status official website to view the status of OpenAI.
Step 2. The green indicator represents a completely operational status.
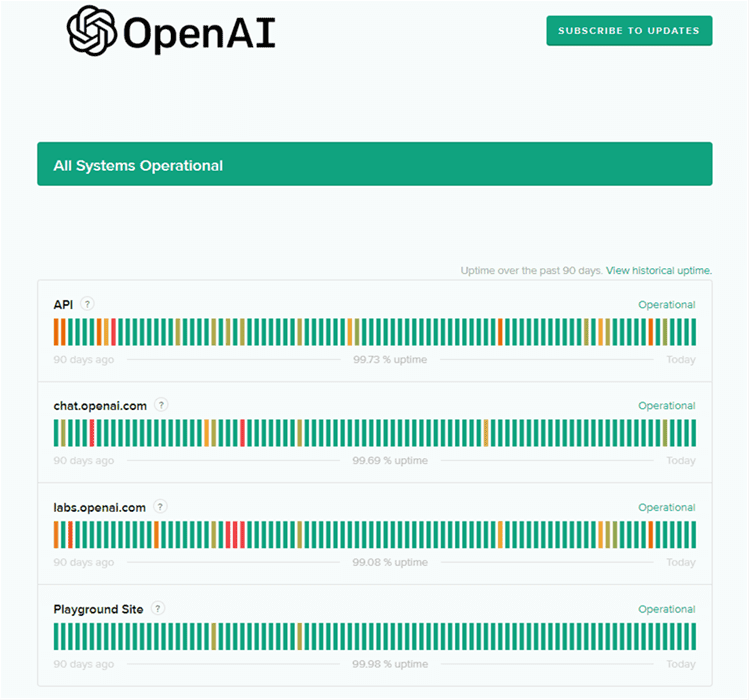
OpenAI Status
Step 3. If you observe red, orange, or pale green lines, there is an outage, and you must wait until the ChatGPT team resolves the issue.
Log out and log in to ChatGPT
When observing excessive requests in one hour try again later, or if you have made too many requests, kindly calm down; you can close and reopen ChatGPT.
This typically clears the error and allows you to continue interacting with the chatbot. If this repair was unsuccessful, the problem may be associated with your OpenAI account.
You may attempt to log out and back into ChatGPT to determine if it has been removed. Alternatively, you can attempt to create a new account.
Further Reading: ChatGPT Login Button Not Working >
Contact OpenAI support
If you cannot access your OpenAI account, you may contact the OpenAI customer care staff for help. They will provide you with more guidance on resolving the problem and getting you back up and running.
Can I Increase my ChatGPT Rate Limit?
If you use the API regularly and want more tokens or requests per minute, you should request an increase in your ChatGPT rate limit. Your subscription plan and model determine the rate limit. ChatGPT Plus members, for example, may utilize GPT-4 with a limit of 25 messages every three hours, but Instruct Davinci users can have up to 3,500 requests per minute and 350,000 tokens per minute.
If the API is in great demand or the system performance is poor, your request for a higher rate limit may be denied. According to OpenAI, the consumption limit will be adjusted according to these parameters, and they anticipate being severely capacity restricted by GPT-4. You may always contact OpenAI support if you have questions regarding your quota or want to seek an increase.
Further Reading: ChatGPT Vs. Davinci: Which Is Better?
Conclusion
ChatGPT You Are Being Rate Limited is prevalent while using the tool because of the requirement for fair use, server capacity control, and overall system reliability. Users may overcome these rate constraints and guarantee a smoother experience by applying the remedies provided in this article. Reduced query frequency and complexity, monitoring API use, establishing usage restrictions, applying exponential backoff, and other strategies are simple to implement. If you have any more queries regarding this problem, please leave comments under this post.


